We, human beings build our words and sentences using characters, that consists of the letters of the alphabet, numbers and other symbols like punctuations, mathematical operators and so on.
Computers only understand numbers, technically the binary number 0 and 1, which can be presented in a decimal, octal, or hexadecimal format, but still, they are only numbers. So how does a computer handle all type of characters?
To bring the two worlds (human and computer respectively) together smart people decided to assign a number to each individual characters, like the decimal 65 is assigned to letter ‘A’, 66 to letter ‘B’ and so on. This way computers still work with numbers in a low level but those numbers now can be presented to a human reader as characters on the screen.
At this point it’s worth to note that in computing numbers are usually used in their hexadecimal format, so you’ll likely see the ASCII value of letter ‘A’ not as decimal 65 but hexadecimal 0x41.
ASCII, UTF-8, UTF-16 and UTF-32 or any other encoding methods have one single purpose: to assign a certain numerical value to a certain character. It’s only the way how they do it differs as we’ll see below in detail.
ASCII
Originally engineers used a single byte to store a single character. A byte consists of 8 bits (one bit is either a 0 or a 1) which means 28 (256) possible values that a byte can store. The English (Latin) alphabet has 26 letters. Even if we assign a different value to lower and uppercase letters individually, we still have plenty of values to assign to decimal numbers. All the printable characters, punctuations and other special characters that has special functions like the ‘null’ character (ASCII 0) that usually marks the end of a string, the line feed character (ASCII decimal 10, or 0xA in hex) or carriage return (ASCII decimal 13, or 0xD in hex) that is widely used to mark the end of a line for the computer system.
To have this standardized, the ASCII table (American Standard Code for Information Interchange) was born in the early 1960s.
By the 1980s it became obvious that 256 characters will not be enough to cover all the characters necessary. Not only the Latin but Cyrillic, Greek, Arabic, Chinese, Japanese and other letters needed to be covered along with a myriad of symbols, emoticons, and so on. In 1988 the Unicode format was born, today the latest version (14.0) contains over 144,000 characters.
To cover this many characters, UTF-8 later UTF-16 and UTF-32 encoding were born. These use between one and four bytes to store a single character. Yes, a character can take up one byte (like the latin ‘A’ letter from the earlier example) or as much as four bytes, (like the smiley emoji).
The computer knows how many bytes belong together based on the first few bits inside them, also the first few bytes of the text file (the Byte-Order Mark or BOM in short) tells the computer what encoding is being used and how to read the files. If you are interested how exactly these look like, keep reading. We cover all these topics for UTF-8, 16 and 32 separately below.
UTF-8
First, we need to talk about two things quickly. One is variable-length encoding and the second is the BOM, or byte-order mark.
Let’s take an example that we can go through to understand these two concepts.
BOM
Start with the concept of BOM. BOM Byte-Order Mark and it’s the first 3 characters of the text file that is saved using the UTF-8, 16 or 32 encoding. This BOM code specifies the encoding type of the file so the text editor will know how to read the contents of text following text in the file.
The following example shows how this looks like in real life.
# Read file PS C:\temp> $StringByteArray = Get-Content bom_UTF-8.txt -Encoding byte # Convert the resulting byte array to hexadecimal values PS C:\temp> [System.BitConverter]::ToString($StringByteArray) EF-BB-BF-74-65-73-74-20-62-6F-6D-20-F0-9F-98-8A-F0-9F-91-8D # Convert byte array back to ASCII string PS C:\temp> [System.Text.Encoding]::ASCII.GetString($StringByteArray) ???test bom ???????? # Convert byte array back to UTF-8 string PS C:\temp> [System.Text.Encoding]::UTF-8.GetString($bytes) test bom 😊👍
Or
PS C:\temp> Format-Hex bom_UTF-8.txt
Path: C:\temp\bom_UTF-8.txt
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
00000000 EF BB BF 74 65 73 74 20 62 6F 6D 20 F0 9F 98 8A test bom 😊
00000010 F0 9F 91 8D ðŸ‘
You see the file starts with three very specific characters: 0xEF, 0xBB, 0xBF which is the BOM code of UTF-8. This tells the editor or text reader (in our case the PowerShell terminal) that the following text is encoded using the Unicode table, so the last eight bytes of the file are technically two Unicode characters encoded in 4 bytes each.
When displayed using regular ASCII encoding, we see the three BOM bytes and the last eight bytes printed out in question marks because the text reader thinks they are regular, unprintable ASCII characters so it substitutes them with question marks.
It’s worth to mention that with UTF-8 the BOM marker is not really needed because the text reader can figure out on its own based on the text contents that it’s UTF-8 encoded.
The Byte-Order Marker will be important with UTF-16 or 32 because it will indicate the endianness or the text flow that might be more difficult for the program to guess on its own. More on this later.
Variable-Length Encoding
As discussed earlier, UTF-8 was designed to handle much more characters than ASCII does. Using the ASCII table you can use up to 256 characters by design. Nowadays UTF-8 encodes over 144 thousand characters! But how does it do that?
UTF-8 uses bytes to store character values in, just like ASCII does. However it can use one, two, three or four bytes for a single character, which might expand the file size a little bit, but gives us the opportunity to have an insane number of character available for us in a simple text file.
But how does the computer know if a four-byte part in the file represents four different characters, or maybe a single unique character only?
Take a look at the following table:
- 1 byte character: 0xxxxxxx
- 2 byte character: 110xxxxx 10xxxxxx
- 3 byte character: 1110xxxx 10xxxxxx 10xxxxxx
- 4 byte character: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
It’s quite simple, isn’t it? If a character (which is a byte, so eight bits long) starts with a zero as the first bit, the computer knows that this single byte represents a single character. If it starts with two one bits followed by a zero, that means it’s a two-byte character. If there are three or four one bits (also closed by a trailing zero) the computer knows to group three or four bytes together respectively to form a single character. As a standard the other bytes in these groups all start with ‘10’ to signal that it’s a part of a character group.
So, let’s see a few examples:
Test.txt is our test file saved using UTF-8 encoding:
A ß 熕 😊
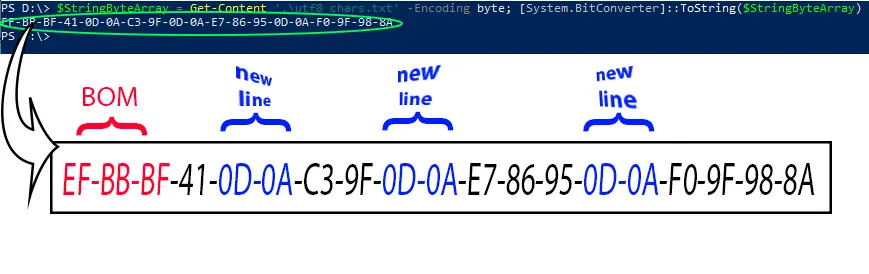
The file starts with the byte-order mark bytes (0xEF, 0xBB, 0xBF), then the four characters with the new line separating them. A carriage return and line feed characters together represent a new line on Windows systems. An interesting fact that Unix-type systems (linux, BSD, MacOS) only use the line feed character for a new line.
Now break down the character bytes to see how they are grouped together.

As expected, the beginning of the first byte marks the length of the character. It’s zero for the single byte character, then 110 for the two-byte long german ß symbol, 1110 for the oriental sign which occupies three bytes and finally 11110 tells the computer that a group of four bytes will form the next character which is a smiley emoji.
If there are multiple bytes for a character, each consecutive bytes start with 10.
After discussing the concepts behind UFT encoding, let’s see how UTF-16 and UTF-32 are different from UTF-8, when they are preferred and why.
UTF-16
While both UTF-8 and UTF-16 store characters in a variable length fashion, the default size of a character is different in both cases. UFT8 uses 8bit (1 byte) length by default for regular (ASCII) characters and only using multiple bytes for special Unicode symbols, UTF-16 uses 16bits as the smallest character unit.
Also, the UTF-16 byte-order mark (BOM) has only two characters: 0xFE,0xFF or 0xFF,0xFE. The former signals that the file is saved in a big-endian format, the latter suggests a little-endian byte order in the file.
But what is endianness? Don’t be discouraged by the strange name, it covers a quite simple principal when it comes to how data is present in a computer system. Endianness simply shows the byte order how characters are stored in memory or in a string.
Big-endian order stores the most significant byte of a string at the smallest memory address, while little endian work the opposite way. For a human reader it means big endian represents bytes in the order how we normally read (from left to right), while little endian reverses that.
Let’s check it out with an example below.
PS C:\temp> $UTF-16BE = Get-Content bom_UTF-16_BE.txt -Encoding byte PS C:\temp> $UTF-16LE = Get-Content bom_UTF-16_LE.txt -Encoding byte PS C:\temp> [System.BitConverter]::ToString($UTF-16BE); [System.BitConverter]::ToString($UTF-16LE) FE-FF-00-74-00-65-00-73-00-74-00-20-00-62-00-6F-00-6D-00-20-D8-3D-DE-0A-D8-3D-DC-4D FF-FE-74-00-65-00-73-00-74-00-20-00-62-00-6F-00-6D-00-20-00-3D-D8-0A-DE-3D-D8-4D-DC

As seen the actual file starts with two BOM (Byte Order Marker) characters showing the computer how to read the file. If the file starts with 0xFE,0xFF the computer knows that consecutive bytes follow a big-endian order, so the letter ‘t’ will be represented as 0x00,0x74. If the order was little-endian, the BOM would read as 0xFF,0xFE telling the computer to expect the two characters representing letter ‘t’ in a reverse order: 0x74,0x00.
UTF-32
Unicode was originally developed as a 16-bit encoding protocol. In 1996, almost a decade after it was born, the protocol was expanded to utilize variable length encoding: UTF-8 uses 1 to 4 bytes to encode a single character, UTF-16 is also a variable length encoding scheme using 2 or 4 bytes, and finally UTF-32 which always represents characters as a fixed length 4-byte value.
Which one is better: UTF-8, UTF-16 or UTF-32?
UTF-8 is the most widely used format of all. Among the three it produces the shortest output after encoding files that mostly contains printable characters (encodes those characters using mostly a single byte, while UTF-16 and UTF-32 both needs two or four bytes for the same content). Therefore UTF-8 is the most popular encoding scheme on the web and when producing text documents.
UTF-16 is mostly deprecated by now (in the western world), it was adopted by legacy Windows and Java systems which benefited from the 16-bit fixed length encoding when the protocol was new. Also, UTF-16 is popular with many non-western languages where characters between Unicode codes U+0800 and U+FFFF are popular because UTF-16 uses only 2 bytes to represent those, while UTF-8 needs 3 bytes to encode them.
UTF-32: because it produces fixed length character values, decoding and manipulation of stored data can be faster in some cases.
If I missed out something please let me know, ping me a comment below.
Comments