In Python there is a built-in Base64 encoder/decoder ready to use. Here is a very simple example on how to encode and decode using the built-in base64 library.
import base64
## ENCODE
# Encode a string in Python 2.7
print (base64.b64encode('String to encode!'))
# Python 3 needs the input string to be presented as a byte array
print (base64.b64encode('String to encode!'.encode()))
## DECODE
# Decode the Base64 code using either Python 2.7 or 3
print (base64.b64decode('U3RyaW5nIHRvIGVuY29kZSE='))
However, in this article we go through the procedure of writing our own Base64 encoder and decoder algorithms from scratch to see exactly how they work.
The Encoder
import sys
def base64encode(s):
i = 0
base64 = ending = ''
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
# Add padding if string is not dividable by 3
pad = 3 - (len(s) % 3)
if pad != 3:
s += "A" * pad
ending += '=' * pad
# Iterate though the whole input string
while i < len(s):
b = 0
# Take 3 characters at a time, convert them to 4 base64 chars
for j in range(0,3,1):
# get ASCII code of the next character in line
n = ord(s[i])
i += 1
# Concatenate the three characters together
b += n << 8 * (2-j)
# Convert the 3 chars to four Base64 chars
base64 += base64chars[ (b >> 18) & 63 ]
base64 += base64chars[ (b >> 12) & 63 ]
base64 += base64chars[ (b >> 6) & 63 ]
base64 += base64chars[ b & 63 ]
# Add the actual padding to the end
if pad != 3:
base64 = base64[:-pad]
base64 += ending
# Print the Base64 encoded result
print (base64)
base64encode(sys.argv[1])
Let's go through the script to see how it works. We start off by defining our function, called base64encode as this way it will be simple to just call the function to convert any number of strings easily. It's a simple function, it takes one input for the string we want to encode.
Then we declare our variables, counters we will use.
Initialization
The base64chars string is very important, it contains the 64 characters we'll map to the actual numbers we get as the result of the encoding process.
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
Add Padding if needed
Next, the algorithm checks if the length of the input string is a multiple of 3. Remember, Base64 works with 3 ASCII character at a time, giving back a 4 character long output as a result. If the last block of the string is less than 3 characters (24bits) long, the program adds a padding character to the string itself, and makes a note of the padding length (one or two) in the "ending" variable, as that will be appended to the end of the encoded result. The padding character can be anything, in our case it's the character 'A' for simplicity. For instance, if the string is 52 characters long, it will add two bytes as padding to make the length dividable by 3.
pad = len(s) % 3
if pad != 0:
while pad < 3:
s += "A"
ending += '='
pad += 1
Build 24bit blocks to be converted
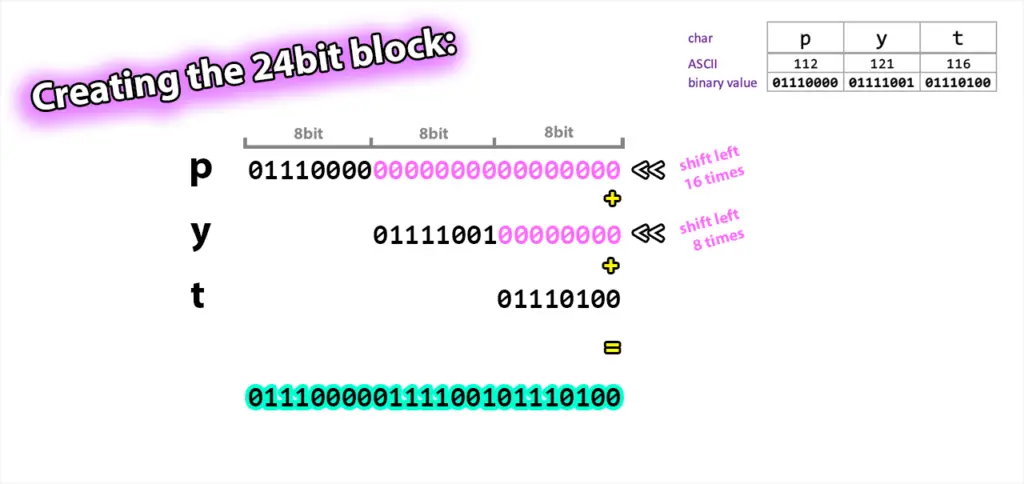
Then the program iterates through the input string, computing with 3-character blocks at a time: first it gets the ASCII code of the first character of the block, puts that value in variable n. Then shifts the binary values to the left 16 times and load it in variable b, which will contain the binary data of this whole block. Remember, the block will be 24 bits long. The first byte - which is 8 bits - will occupy the first third of the block, the second byte will be loaded in the middle, and the third byte is put in the last section of the 24-bit variable.
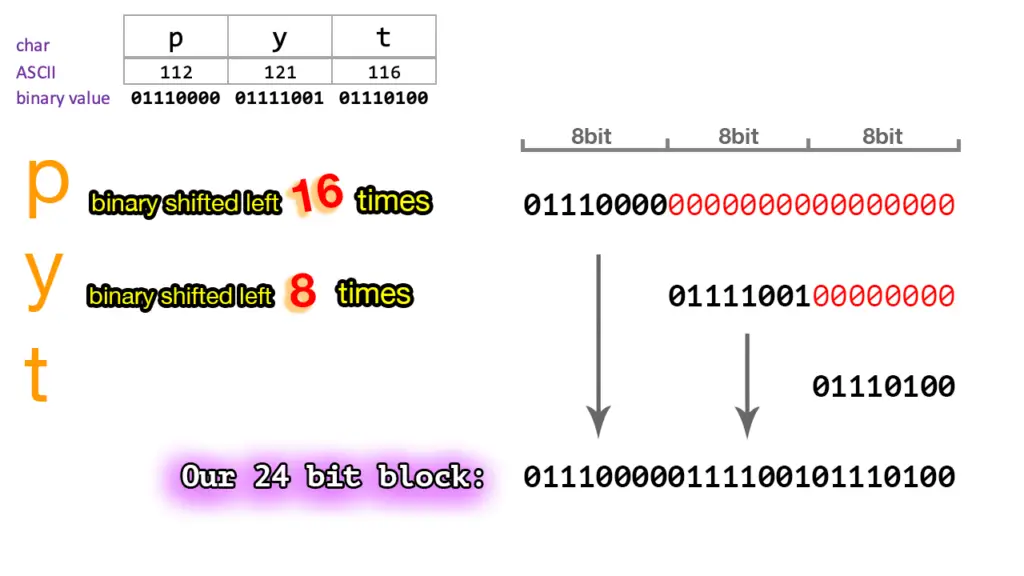
Convert to Base64
Next step is the actual conversion. The program splits our 24bit block into 6bit numbers, then maps those numbers to the corresponding text character based on the Base64 table.
# Convert the 3 chars to four Base64 chars
base64 += base64chars[ (b >> 18) & 63 ]
base64 += base64chars[ (b >> 12) & 63 ]
base64 += base64chars[ (b >> 6) & 63 ]
base64 += base64chars[ b & 63 ]
What this code does is shifting the bits in the block right, then uses a mask to null out the bits in front of the actual 6-bit results. And so does it four times, as the 24-bit block contains 4x 6bit parts. Here's an illustration to make more visual what's happening:
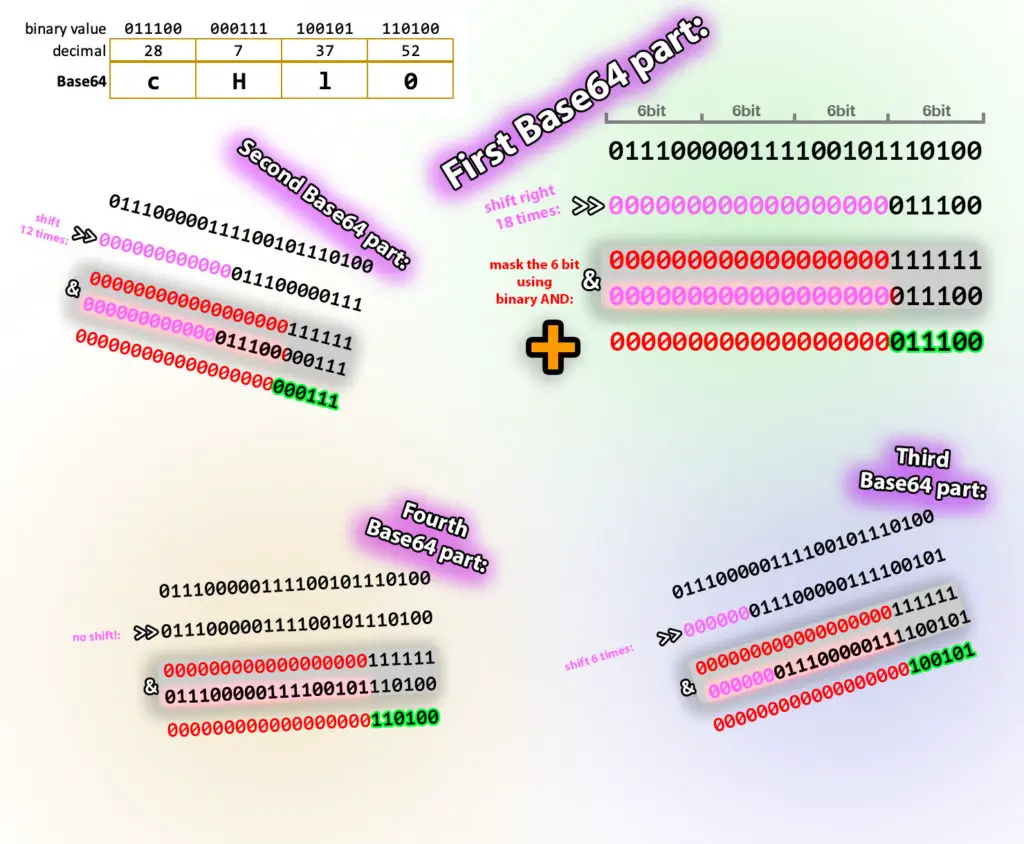
To calculate the first 6bit part, the program shifts the 24-bit block to the right 18 times, this way the desired 6 bits will occupy the first 6 bits of the block. Check the illustration above. You'll see in our example the last 6bits of the shifted block will become 011100. Running the AND operator between this and the decimal number 63 (which is …111111 in binary) is not necessary this time as all of the bits in front of the shifted block are all 0s.
Now, the second part is more interesting. The program shifts the block 12 times, so the second 6 bits gets to the far-right position that we need. But we still have the first 6 bits in the shifted block. It reads as 011100000111. How can we discard the first, unneeded 011100 part? The algorithm simply uses the AND bitwise operator to accomplish it. Running AND on the corresponding bits of the shifted block and the number 63 (again, all zeroes, plus 111111) will do just this for us. Think about it: performing AND between anything and 0 will produce 0. On the contrary, the last six 1s of the mask will leave the shifted block intact.
The same logic applies to the other two parts also.
After getting the numeric value of the 6bits of the encoded block, the program maps the numeric value to a character in the base64chars array. Simply put, our first Base64 number is 28, so it will use the 29th character in the base64chars array, which is c. 29th, because indexing starts with 0, not one. Meaning base64chars[0] is A, base64chars[1] will retrieve B, etc.
It does it with all other characters, adding them to the "base64" string, which will contain our final encoded text.
Padding
As the last step, the algorithm also adds the "ending" string to the final encoded array. Namely one or two '=' signs, depends on the size of the original string.
See how encoding "" looks like:

The Decoder
Decoding a Base64 encoded string is just the reverse of the encoding process. The program first removes padding and saves the length (one or two chars) for later. This way it knows how many characters to discard at the end of the process. Then it converts the characters in the string to numbers between 0 and 63, using the same base64chars array then before. Next it creates blocks with four characters at a time (4x6bit = 24bit), that will be divided into three 8bit pieces. Those 8bit numbers are essentially the ASCII codes of the decoded text, so they just need to be concatenated together and after discarding the extra padding at the very end of the string, we get our original string back.
import sys
def base64decode(s):
i = 0
base64 = decoded = ''
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
# Replace padding with "A" characters so the decoder can process the string, and save the padding length for later
if s[-2:] == '==':
s = s[0:-2] + "AA"
padd = 2
elif s[-1:] == '=':
s = s[0:-1] + "A"
padd = 1
else:
padd = 0
# Take 4 characters at a time
while i < len(s):
d = 0
for j in range(0,4,1):
d += base64chars.index( s[i] ) << (18 - j * 6)
i += 1
# Convert the 4 chars back to ASCII
decoded += chr( (d >> 16 ) & 255 )
decoded += chr( (d >> 8 ) & 255 )
decoded += chr( d & 255 )
# Remove padding
decoded = decoded[0:len( decoded ) - padd]
# Print the Base64 encoded result
print (decoded)
base64decode(sys.argv[1])
Initialization
The program declares the variables, counters and the base64chars map.
Remove padding
After the encoding process, if the length of the original string was not the multiple of 3, the encoder appended one or two '=' characters, marking how many padding characters are there to be discarded after decoding.
Earlier our encoder encoded the string ' python base64 text test :)'. It was 26 characters long, so the program needed to add one padding byte to the end, which is in our script an "A" character. It really can be anything, as it is discarded during the decoding process.

Building 24bit blocks
After the '=' characters are removed, the program iterates through each character in the encoded input string. It takes groups of four characters at a time, and concatenates them, the same way it did during the encoding process with the three bytes there. As a result, we get a 24bit block again.
Extract the 3 byte decoded characters from the 24bit blocks
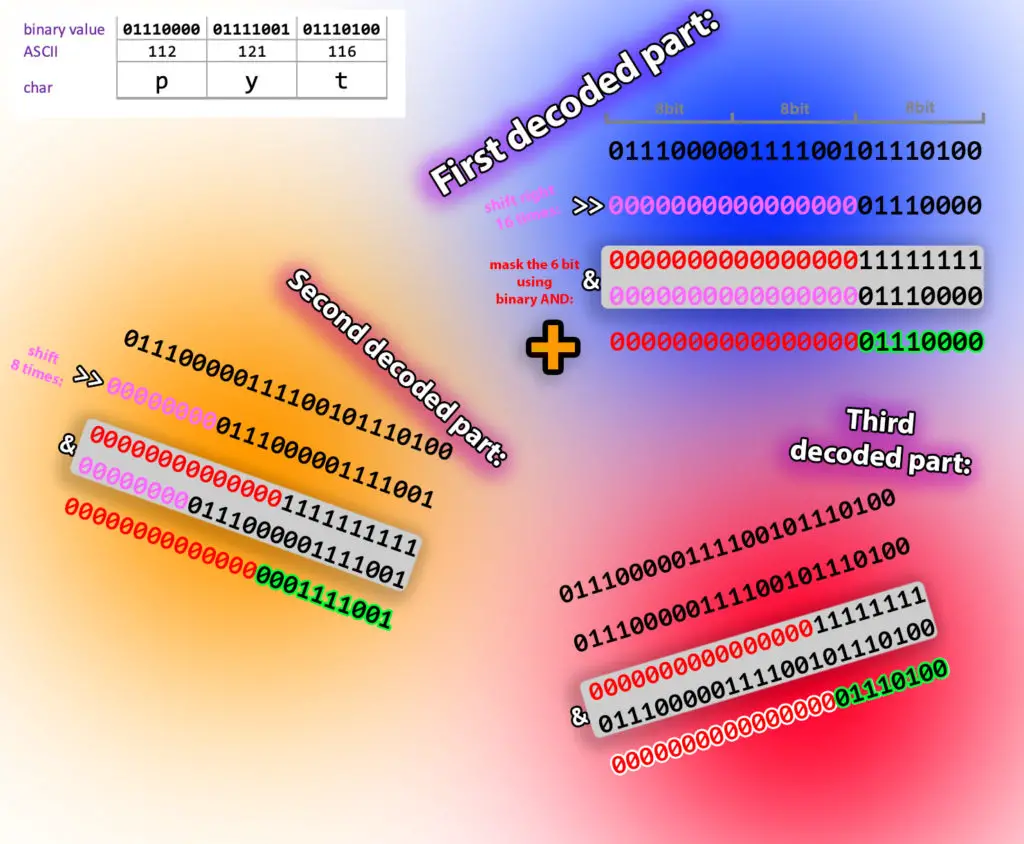
Now all the program needs to do is splitting the 24bit blocks in 3x 8bit pieces. Those 8bit numbers are actually the ASCII codes of the decoded characters.
Like it was done during the encoding process, the first byte is extracted by shifting the 24bit block right 16 times, then the first 16 bits are nulled out by running and AND operation on the shifted block and number 255 (in binary: 00000000 00000000 11111111).
Then to get the second byte, the block is only shifted 8 times, and masked with 255 again.
The last byte doesn't need shifting, just discarding the first 16 bits by the masking trick.
Remove padding
The last step is removing the padding bytes from the end of the decoded string, and we get the original content back as seen in this example.

There are a couple of problems with this. First, the initial use of base64.b64encode() requires a byte string, so prefixing a ‘b’ to the string makes it work.
Second, the algorithm fails to match the Linux base64 program (usually found in /usr/bin/base64). It works for strings exactly divisible by 3, but fails to match it on any other length string.
For instance, storing the string “abc” in the file named “key” gives the proper result for both–“YWJj”. But running the algorithm on “abcd” gives the incorrect result of “YWJjZEFB==” instead of the correct result of “YWJjZA==”. Likewise, running the algorithm on “abcde” gives “YWJjZGVB=” instead of the correct “YWJjAGU=”.
The problem is with the padding. The algorithm adds one or two “A”s, which doesn’t properly zero out the last 8 or 16 bits. Since it has padded on extra “A”s, it also adds “=” signs unnecessarily, lengthening out the string.
Here’s an impl that works with ascii and binary strings:
#!/usr/bin/env python3
import sys
tab = ‘ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/’
def encode(s):
ending = ”
encoded = ”
# Convert s into a binary bit stream
b = ”
if type(s) is str:
for c in s:
b += ‘{:08b}’.format(ord(c))
elif type(s) is bytes:
for c in s:
b += ‘{:08b}’.format(c)
# Add zero bits, if needed
if len(s) % 3 == 1:
b += ‘0000’
ending += ‘==’
if len(s) % 3 == 2:
b += ’00’
ending += ‘=’
# Grab bits in 6-bit chunks, convert them to a number and
# look them up in tab.
for i in range(0, len(b), 6):
index = int(b[i:i+6], 2)
encoded += tab[index]
encoded += ending
return encoded
def decode(s):
decoded = b”
# Strip off any terminating “=” signs.
# Look each char up in the tab, get the associated index, and
# convert that to binary, then rechunk on 8-bit boundaries.
b = ”
for i in s.rstrip(‘=’):
idx = tab.index(i)
b += ‘{:06b}’.format(idx)
for i in range(0, len(b), 8):
decoded += bytes([(int(b[i:i+8], 2))])
# Strip off terminating null
return decoded[:-1]
Thank you uber for your insights, Python 3 indeed needs a byte array declared, and the padding logic in the script is fixed.